Occurrence clustering
There might be duplicated records in the GBIF index. Some records may have the same date, scientific name, catalogue number and location but come from two different publishers or have slightly different attributes.
There are many valid reasons why these duplicates appear on GBIF. Sometimes an observation was recorded in two different systems, sometimes several records correspond to herbaria duplicates (you can check the work of Nicky Nicolson on the topic), sometimes a specimen was digitized twice, sometimes a record has been enriched with genetic information and republished via a different platform…
This is why we released an experimental data-clustering feature aiming to identify potentially related records on GBIF. The goal was not only to detect potential duplicates but to also find interesting relationships, such as between typification records or records originating from Natural History collections, DNA-derived sequences and citations of materials examined when publishing taxonomic treatments in journal articles.
Records that have been included in a cluster can be found with the “is in cluster” filter in the occurrence search. Each occurrence page belonging to a cluster will have a “CLUSTER” tab displaying the potentially related records (see a screenshot of this example below).
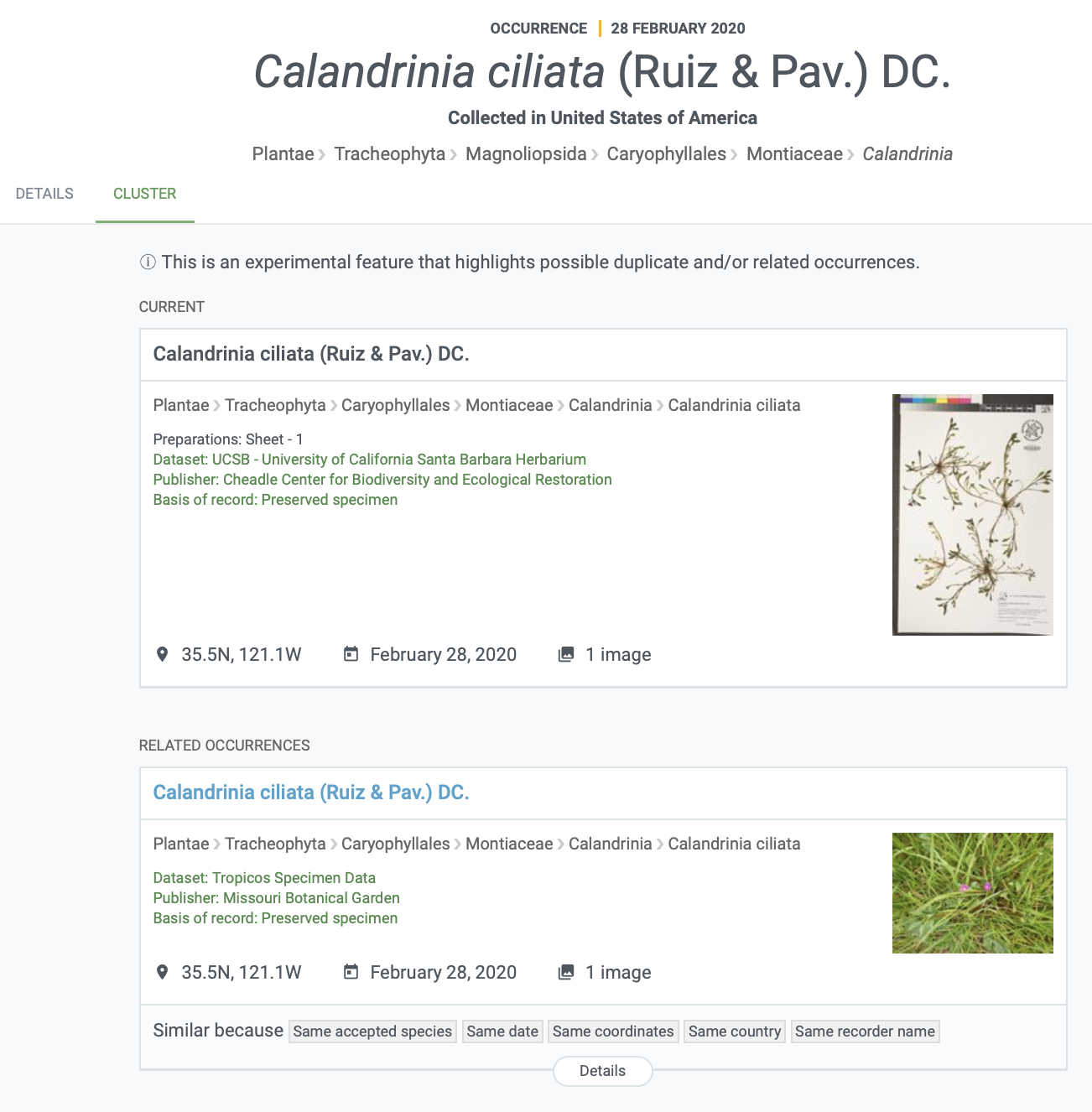
You can read this news item for more information and some exciting examples.
Clustering records
Step 1: Select candidates
Comparing nearly 2 billions records with each other is very resource intensive and quite impractical, so the first step of the data-clustering process is to select and group candidate records to compare.
To help avoid dubious connections, only records matched to a species or a more specific rank in the taxonomic backbone are eligible for clustering. Similarly, records flagged as being matched to a higher taxon are excluded.
For the remaining eligible records, the system first creates a series of "hashes" based on specified fields. All records sharing a hash are candidates to compare against each other.
For example, one of the "hashes" used is based on the species key, rounded coordinates, year, month and day. This means that the records that share the same values for those fields will be grouped together in the candidate table for further inspection.
The fields used to identify and group the candidates are a subset of what is used later on for comparing them (see the table below). See the source code to check the details.
Step 2: Compare and assess
In this second phase, the system will compare all records in the candidate set to each other and generate assertions. The assertions are inspected and the algorithms decides if there is enough evidence in the assertions to create a relationship between them.
The table below summarizes how those assertions are made but for more details, check the source code.
| Assertion | Fields checked | Condition checked |
|---|---|---|
Same specimen |
|
same taxonKey between records and typeStatus is "Holotype" for both records |
Typification relation |
|
same between records |
Same accepted species |
|
same between records |
Same date |
|
same between records |
Approximate date |
|
dates one day apart |
Different date |
|
differs between records |
Non conflicting date |
|
no date on either record |
Same recorder name |
|
same between records |
Same coordinates |
|
same between records |
Non conflicting Coordinates |
|
no coordinate on one or both sides |
Within 200 m |
|
distance ≤ 0.200km |
Within 2 km |
|
distance ≤ 2.00km |
Same country |
|
same between records |
Non conflicting country |
|
country only on one record |
Different country |
|
differs between records |
Identifiers overlap |
|
checks any overlap of identifiers between records |
Other catalogue number overlap |
|
checks if the other catalogue number correspond to the institution code, collection code and catalogue number from another record |
Is from sequence repository |
|
checks if one of the datasetKey corresponds to one of the sequence repository datasets: INSDC sequences, INSDC host organisms, INSDC environmental samples, iBOL (see keys |
Are specimens |
|
checks if the basis of record for both records are one of the following: |
The table below summarizes the combinations of assertions that are sufficient to link the records in a cluster. If a group of occurrences share the combinations of assertions for any given column, they will be clustered together.
| Assertion | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Same specimen |
x |
|||||||||||||
Typification relation |
x |
|||||||||||||
Same accepted species |
x |
x |
x |
x |
x |
x |
x |
x |
x |
x |
||||
Same date |
x |
x |
x |
x |
||||||||||
Non-conflicting date |
x |
x |
x |
x |
||||||||||
Approximate date |
x |
x |
||||||||||||
Same coordinates |
x |
x |
x |
|||||||||||
Non-conflicting coordinates |
x |
x |
||||||||||||
Within 200m |
x |
x |
||||||||||||
Within 2km |
x |
x |
x |
|||||||||||
Identifiers overlap |
x |
x |
x |
x |
x |
x |
||||||||
Other catalogue number overlap |
x |
|||||||||||||
Same recorder name |
x |
x |
||||||||||||
Is from sequence repository |
x |
|||||||||||||
Are specimen |
x |
Any group of occurrence associated with the assertion Different date or Different country will not be clustered together.
|
Why are some occurrences not clustered?
It is possible that some occurrences check one of the combinations of assertions but aren’t shown as clustered yet. This could be the case for several reasons:
-
The occurrences are newly published. Right now, the clustering process is quite resource intensive and doesn’t run automatically. We need to trigger it manually. This means that it can take a few weeks before newly published occurrences get clustered.
-
The "duplicates" come from the same dataset. The clustering algorithm only compares occurrences across datasets, not within datasets.
-
There can be a delay between the moment the occurrences are clustered and the moment they become searchable with the "is in cluster" filter (this is due to some technical reasons a bit too long to explain in this post, but relate to updating the search indexes separately from the clustering table)
There could be other unforeseen reasons, and if in doubt, please contact us at helpdesk@gbif.org.
Improve linkage
If for one reason or another, you need to publish on GBIF occurrences for observations or specimens that you know are already on GBIF, how best to do it?
-
Make sure that you reuse the same identifiers as much as possible, including the formating. Same catalogue numbers, occurrenceID, etc.
-
Use the associatedOccurrences term and resource relationship extension. These are not used during the clustering today, but are expected to be in the future, and are the correct way to communicate relationships within Darwin Core.